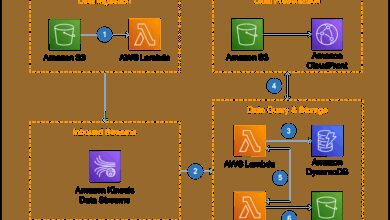
Ever wondered what’s really happening behind the scenes when AWS seems slow or down? Understanding AWS status isn’t just for IT pros—it’s crucial for anyone relying on cloud services. Let’s dive into the real story behind AWS status updates, outages, and how to stay ahead of disruptions.
What Is AWS Status and Why It Matters

The term aws status refers to the real-time health and operational condition of Amazon Web Services’ global infrastructure. It’s a vital resource for developers, businesses, and cloud architects who depend on AWS for mission-critical applications. Monitoring aws status helps organizations anticipate, respond to, and mitigate service disruptions.


Definition and Purpose of AWS Status
AWS status is a public-facing dashboard maintained by Amazon that reports the operational health of its cloud services across multiple regions. It provides transparency about ongoing incidents, scheduled changes, and service performance. The primary goal is to keep users informed about potential issues that could affect their applications.
According to AWS’s official status page, the system is designed to deliver timely, accurate, and actionable information. This includes service degradation, outages, and recovery timelines.
How AWS Status Impacts Business Operations
When a critical AWS service like EC2, S3, or Lambda experiences an issue, the ripple effect can be massive. E-commerce platforms, streaming services, and SaaS applications may face downtime, leading to revenue loss and reputational damage.
- Financial losses due to downtime can exceed $500,000 per hour for large enterprises.
- Customer trust erodes quickly during prolonged outages.
- Compliance risks arise if SLAs (Service Level Agreements) are violated.
“Transparency during outages is not just a courtesy—it’s a competitive advantage.” — AWS Senior Solutions Architect
How to Access and Interpret AWS Status
Navigating the aws status dashboard effectively requires knowing where to look and how to interpret the data. Whether you’re a developer or a CTO, understanding this tool is essential for proactive cloud management.
Navigating the AWS Service Health Dashboard
The AWS Service Health Dashboard (status.aws.amazon.com) is the primary source for real-time updates. It displays a color-coded grid showing the status of each service in every AWS region.
- Green: Service is operating normally.
- Yellow: Degraded performance or partial outage.
- Red: Service disruption or complete outage.
- Grey: No issues reported or service not available in that region.
Each entry links to detailed incident reports, including start time, impact description, and resolution updates.
Understanding Incident Types and Severity Levels
AWS categorizes incidents based on scope and impact. These classifications help users assess risk and prioritize responses.
- Informational: Scheduled maintenance or low-risk changes.
- Investigating: AWS is aware of an issue and gathering data.
- Impaired Service: Partial functionality loss.
- Service Disruption: Major or total outage.
- Resolved: Issue has been fixed and service restored.
For example, in the December 2021 US-East-1 outage, AWS labeled it as “Service Disruption” due to widespread impact on EC2, RDS, and S3 services.
Common Causes of AWS Service Disruptions
Even the most robust cloud platforms experience hiccups. Understanding the root causes behind aws status alerts can help organizations prepare better and reduce dependency risks.
Network and Infrastructure Failures
Despite AWS’s redundancy, network routing issues, power failures, or hardware malfunctions can trigger outages. In 2023, a fiber cut in Northern Virginia disrupted several availability zones in the US-East-1 region.
These physical layer issues are rare but impactful. AWS mitigates them through multi-AZ architectures and automated failover systems.
Human Error and Configuration Mistakes
One of the most common causes of AWS outages is human error. Misconfigured firewalls, incorrect IAM policies, or accidental deletion of critical resources can cascade into larger issues.
- In 2017, an S3 outage in US-East-1 was caused by a typo during a debugging command.
- Over 150 services were affected, including Slack, Trello, and Quora.
- AWS later implemented stricter change control protocols.
“The most dangerous tool in cloud computing is a human with admin access.” — Cloud Security Expert
Software Bugs and Deployment Glitches
Even automated systems aren’t immune to bugs. Software updates, firmware patches, or orchestration errors can lead to unexpected behavior.
In 2022, a Lambda function throttling issue was traced back to a faulty auto-scaling algorithm. AWS rolled back the deployment within two hours, but many serverless applications experienced latency spikes.
Monitoring Tools for AWS Status Beyond the Dashboard
While the official aws status page is essential, relying solely on it isn’t enough. Proactive teams use additional tools to gain deeper insights and faster alerts.
Third-Party Monitoring Services
Platforms like Datadog, New Relic, and UptimeRobot offer enhanced monitoring capabilities. They integrate with AWS APIs to provide real-time alerts, historical trend analysis, and cross-service correlation.
- Datadog’s AWS integration tracks over 100 services and sends Slack/email alerts.
- UptimeRobot offers synthetic monitoring by simulating user requests globally.
- CloudHealth by VMware provides cost and performance insights alongside health monitoring.
These tools often detect issues before AWS officially reports them, giving teams a crucial head start.
Using AWS CloudWatch and EventBridge for Real-Time Alerts
AWS provides native tools like CloudWatch and EventBridge to monitor resource health and automate responses.
- CloudWatch collects metrics, logs, and events from AWS resources.
- You can set alarms for CPU usage, latency, or error rates that may indicate underlying issues.
- EventBridge allows you to react to AWS service events (e.g., EC2 instance termination) with automated workflows.
For example, you can configure an EventBridge rule to trigger an SNS notification whenever the AWS Health service reports an event in your region.
Historical AWS Outages: Lessons Learned
Reviewing past aws status incidents reveals patterns and teaches valuable lessons about resilience, architecture, and communication.
The 2017 S3 Outage: A Case Study in Cascading Failure
On February 28, 2017, a simple typo during a command to remove capacity from the S3 billing system caused a major outage in the US-East-1 region.
- The command inadvertently took a large set of servers offline.
- S3 became unreachable for over four hours.
- Thousands of websites and apps were affected.
AWS responded by improving its internal tooling to prevent similar mistakes and introduced rate-limited administrative commands.
The 2021 Christmas Eve Outage: Global Impact
On December 24, 2021, AWS experienced one of its most widespread outages, affecting services across North America and Europe.
The root cause was a networking issue in the US-East-1 region that impacted the AWS internal network, including authentication and routing systems.
- Services like Netflix, Disney+, and Amazon.com were disrupted.
- Many companies relying on AWS for authentication (via Cognito or IAM) faced login failures.
- Restoration took over eight hours due to the complexity of the control plane failure.
This incident highlighted the risks of over-reliance on a single region and the importance of multi-region architectures.
How AWS Improved Resilience After Major Incidents
Following major outages, AWS has made significant investments in system resilience and operational transparency.
- Enhanced change management processes with mandatory peer reviews.
- Improved isolation between control and data planes.
- Expanded regional redundancy and launched new Local Zones and Wavelength Zones.
- Introduced the AWS Resilience Hub to help customers assess application resilience.
These changes reflect a shift from reactive to proactive resilience engineering.
Best Practices for Responding to AWS Status Alerts
When the aws status dashboard turns yellow or red, your response can make the difference between a minor blip and a business crisis.
Developing an AWS Incident Response Plan
Every organization using AWS should have a documented incident response plan. This includes roles, communication channels, escalation paths, and recovery procedures.
- Designate an incident commander during outages.
- Use tools like PagerDuty or Opsgenie for alert routing.
- Maintain a runbook with common troubleshooting steps.
Regularly test your plan with simulated outage drills.
Communicating with Stakeholders During Downtime
Transparency builds trust. When AWS reports an issue, keep your internal teams and customers informed.
- Send timely updates via email, status pages, or social media.
- Avoid technical jargon; focus on impact and expected resolution time.
- Use a public status page (e.g., using Statuspage.io) to show real-time updates.
“During an outage, silence is worse than bad news.” — CTO of a Fortune 500 Tech Company
Future of AWS Status: Trends and Predictions
The way we monitor and respond to aws status is evolving. New technologies and practices are shaping a more resilient and transparent cloud ecosystem.
AI-Powered Anomaly Detection and Predictive Alerts
AWS is investing heavily in machine learning to predict failures before they occur. Services like Amazon DevOps Guru use AI to analyze logs and metrics for early warning signs.
- It can detect unusual API error spikes or latency patterns.
- Predicts potential outages hours in advance.
- Integrates with CloudFormation and CodePipeline for automated remediation.
This shift from reactive to predictive monitoring is a game-changer for cloud reliability.
Increased Transparency and Real-Time Reporting
Users are demanding more detailed and faster updates. AWS has responded by improving the granularity of its status reports.
- Now includes root cause analysis (RCA) within 48 hours of major incidents.
- Provides timeline breakdowns with minute-by-minute updates.
- Offers RSS feeds and webhook integrations for real-time delivery.
Future enhancements may include live video briefings or interactive outage maps.
The Role of Multi-Cloud and Hybrid Strategies
As businesses seek to reduce dependency on a single provider, multi-cloud strategies are gaining traction.
- Using Azure or Google Cloud as a backup for critical AWS workloads.
- Leveraging Kubernetes (EKS, AKS, GKE) for portability.
- Implementing hybrid models with on-premises failover.
While AWS remains dominant, diversification is becoming a key risk mitigation strategy.
What is the AWS status dashboard?
The AWS status dashboard (status.aws.amazon.com) is a public website that provides real-time information about the operational health of AWS services across all regions. It shows service availability, ongoing incidents, and resolution updates.
How often is AWS status updated?
AWS status is updated in real-time. The dashboard refreshes automatically, and new incidents are posted as soon as they are detected. Major updates during outages are typically issued every 15–30 minutes.
Can I get AWS status alerts via email or SMS?
Yes. You can subscribe to RSS feeds or use AWS SNS (Simple Notification Service) to receive alerts. Third-party tools like Datadog or StatusGator also offer email, SMS, and Slack notifications for AWS status changes.
What should I do if my service is down but AWS status shows green?
If AWS reports normal operations but your application is affected, the issue may be local to your configuration. Check CloudWatch logs, VPC flow logs, and security groups. It could also be a regional edge issue not reflected in the main dashboard.
Does AWS provide post-mortems for outages?
Yes. AWS publishes detailed post-incident analysis (PIAs) for major outages, usually within 48 hours. These include root cause, timeline, impact assessment, and corrective actions. They are available on the AWS Compliance page.
Understanding aws status is no longer optional—it’s a business imperative. From real-time dashboards to AI-driven predictions, the tools and knowledge exist to minimize disruption. By leveraging official resources, third-party monitors, and robust response plans, organizations can turn cloud volatility into resilience. The future of cloud reliability isn’t just about uptime; it’s about preparedness, transparency, and adaptability. Stay informed, stay ready.
Further Reading: